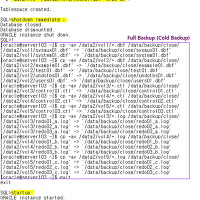
startup 이나 recover 명령어가 실행되면
우선 서버프로세스는 DB에 문제가 있는지 없는지 확인하기 위해 Control File을 읽음.
Control File의 위치는 Parameter File에 있음
Control File에는 DB 운영에 있어 중요한 파일들 등 서버의 여러가지 정보가 들어있는데
복구에 관련된 정보는 checkpoint SCN 관련 정보와 각종 파일의 이름과 위치가 들어있음
DB STARTUP 단계
STARTUP ------> NOMOUNT -------> MOUNT -------> OPEN
parameter file control file redo log file, datafile
1. NOMOUNT
--> 서버 프로세스가 parameter file를 PGA로 읽어들여
해당 parameter file에서 지정한 대로 instance를 생성
2. MOUNT
--> parameter file에 기록된 control file를 읽어 장애를 복구하거나, 유지 관리 작업 등의 작업을 하는 단계
세부적으로 보자면
- CKPT 프로세스가 모든 control file을 읽고 일시적으로 lock을 설정
- Control file header 정보를 검사해 control file에 이상이 없는지 확인 후 MountID를 계산해 control file에 저장
- Parameter file의 DB name 과 control file의 DB name이 동일한지 검사
- 이상이 없으면 alert log file에 메시지 기록 후 mount 완료
3. OPEN
--> Data file header 부분의 정보와 control file 정보를 서로 비교해서 장애 유무를 판단,
이 때 사용되는 것이 checkpoint SCN 정보임
※ Data File의 SCN ※
SCN --> System Change Number, 데이터베이스의 전체 공통번호, datafile의 SCN과 동일해야 DB open 가능
Checkpoint CNT --> 각 테이블스페이스 별로 데이터를 내려쓰는 횟수를 의미
Checkpoint SCN --> 현재까지 저장 완료된 SCN
Stop SCN --> 신규로 추가되는 데이터의 마지막 SCN,
신규로 추가되는 SCN은 현재 작업중이기 때문에 몇 번까지 들어올지 몰라서
DB가 open상태이면 stop SCN을 무한대(0xffff.ffffffff)로 설정됨
정상적으로 DB 종료 --> checkpoint 발생 --> Checkpoint SCN 과 Stop SCN이 동일해짐
비정상적으로 DB 종료 --> checkpoint SCN과 Stop SCN이 동일하지 않음 --> Instance recovery 필요
(stop SCN가 0xffff.ffffffff로 계속 되어있으면 open 중에 종료되었다는 말)
Checkpoint SCN 이후꺼부터 recovery 시작
복구 원리
Recover 명령어나 Startup 명령어가 수행되면
Control File에 있는 모든 데이터 파일의 checkpoint cnt 번호와
Control File내의 data file records 부분에서 checkpoint cnt 부분의 번호와 같은지 비교
각 데이터 파일의 헤더에 있는 checkpoint SCN이 control file 안에 있는 stop SCN 번호와 같은지 비교
일치할 경우 복구 필요없지만 다르면 복구 시도
데이터 파일에 부족한 SCN 중에서 가장 낮은 SCN이 몇번인지 확인
Control file 안에 있는 Log File Records를 찾아
데이터 파일과 컨트롤 파일에서 차이나는 scn 부분을 redo log file 부분에서 low scn 부분을 확인해 필요한 내용이 들어있는 파일을 찾아 그 경로로 가서 복구 내요응ㄹ 읽어서 필요한 로그 파일을 순차적을 적용시킴
적당한 redo log file을 찾으면 가장 낮은 SCN 번호부터 Roll Forward
Roll Forward 끝나면 commit이 수행되지 않은 트랜잭션을 찾기위해 undo$ 딕셔너리를 찾아
거기서 active한 undo segment를 찾고 commit 안된 데이터를 roll backward 한다.
즉!
컨트롤 파일의 STOP SCN 정보와 데이터 파일의 CHECKPOINT SCN 정보를 비교해 동일하지 않을 경우
차이나는 부분을 Redo Log File이나 Archive Log File에서 찾아서 복구
Recovery 종류
Crash Recovery = Instance Recovery
운영 중이던 DB가 비정상적으로 종료된 것을 startup 시에 online redo log file를 사용해 자동적으로 recovery 하는 것
즉, redo log file에 고쳐야 되는 내용이 들어있으면 smon이 자동적으로 복구 작업
Media Recovery
file 삭제나 disk fail등의 이유로 instance recovery 실패할 경우
직접 수동으로 백업 파일 등을 복원 후, online redo log file 과 archived redo log file을 사용해 recovery 하는 것
고쳐야 되는 내용이 archived log file에 있을 경우 수동으로 복구 작업
alert log 파일 위치
/app/oracle/diag/rdbms/testdb/testdb/trace/alert_testdb.log
'오라클 백업/복구' 카테고리의 다른 글
| Data File 장애 복구 1 - No Archive Log Mode 복구 (0) | 2013.01.27 |
|---|---|
| Parameter File 장애 복구 (0) | 2013.01.27 |
| 일자별 자동으로 백업수행 스크립트 (0) | 2013.01.23 |
| Oracle Backup (0) | 2013.01.23 |
| SYS 계정 암호설정과 암호파일 관리 (0) | 2013.01.22 |